Régression multiniveau
Bases théoriques
Dans un modèle multiniveau, les individus sont imbriqués dans des groupes, qui sont eux-encore imbriqués dans des contextes particuliers. Il y a donc plusieurs niveaux. Il n'est donc pas possible d'effectuer une régression simple sur les données, puisque celle-ci nécessite l'indépendance des individus. Or, dans un modèle hiérarchique, les individus sont dépendants des niveaux supérieurs, c'est-à-dire que les différences entre les individus dépendent du groupe de chaque individu, etc.
Si nous pouvions donc représenter la régression simple à l'aide d'une pente:
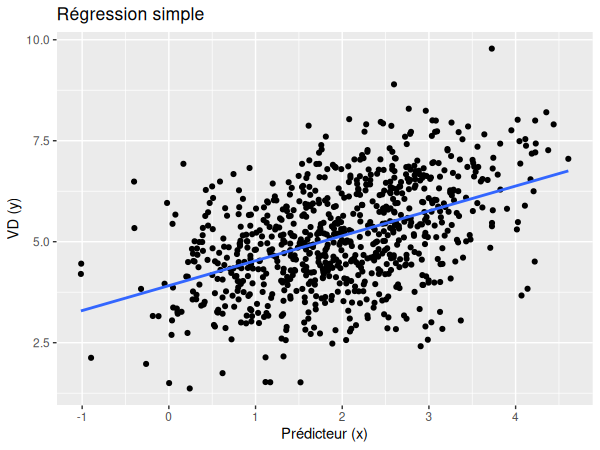
Nous pouvons maintenant prendre en compte les niveaux supérieurs et réaliser plusieurs lignes de régression distinctes:
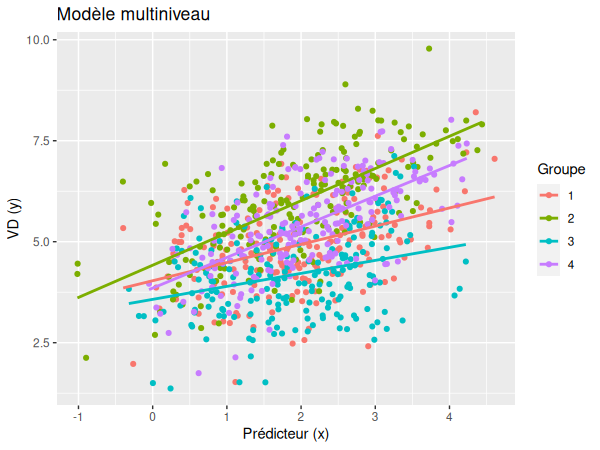
En réalité, les deux sont nécessaire. La pente de régression simple de tous les groupes ensemble est appelée pente fixe et son intercept est appelé intercept fixe. Cela constitue ce que l'on appelle l'effet fixe, car il ne change pas en fonction des groupes. Les pentes pour chaque groupe, elles, s'appellent les pentes aléatoires et leurs intercepts sont nommés intercepts aléatoires, ce qui constitue les effets aléatoires — qui sont différents pour chaque contexte.
L'équation de la régression multiniveau est donc la suivante:

Avec:
- γ00 l'intercept moyenne
- r0j la déviation spécifique au groupe de l'interception moyenne
- r10 la pente moyenne
- r1j la déviation spécifique au groupe de la pente moyenne
- εij l'erreur standard de chaque individu par rapport au groupe
Application
# Soit y la variable dépendante, x le prédicteur et g le groupe
library(lmerTest)
m <- lmer(y ~ x + (x | g), data=data)
summary(m)
Conditions d'application
Conditions d'application
Pour pouvoir être utilisée, la régression multiniveau requiert:
- Au moins 20 unités au niveau 2 (au moins 20 groupes dans lesquelles sont imbriquées les données).
- La distribution normale des résidus (distribution normale des erreurs).
D'autres conditions doivent être également remplies, mais elles ne sont pas abordées dans le cours en raison de leur complexité.
Pour tester la distribution normale des erreurs, nous pouvons réaliser un graphique Q-Q:
# Soit m le modèle de régression
qqnorm(resid(m))
qqline(resid(m))
Nous pouvons également visualiser la distribution des erreurs dans un histogramme:
# Soit m le modèle de régression
hist(resid(m))
Exemple
Voici nos données et notre fichier d'analyse:
| Fichiers |
|---|
| multilevel-regression.csv |
| multilevel-regression.R |
Commençons par activer les librairies nécessaires dans R:
library(lmerTest)
library(ggplot2)
Puis, importons nos données:
df <- read.csv("multilevel-regression.csv")
df$groupe <- as.factor(df$groupe)
Nous pouvons maintenant visualiser la pente fixe ainsi que les pentes aléatoires:
ggplot(data=df, aes(x=predicteur, y=score)) +
geom_point()+
geom_smooth(method=lm, se=F) +
ggtitle("Effets fixes") +
xlab("Prédicteur") +
ylab("Score")
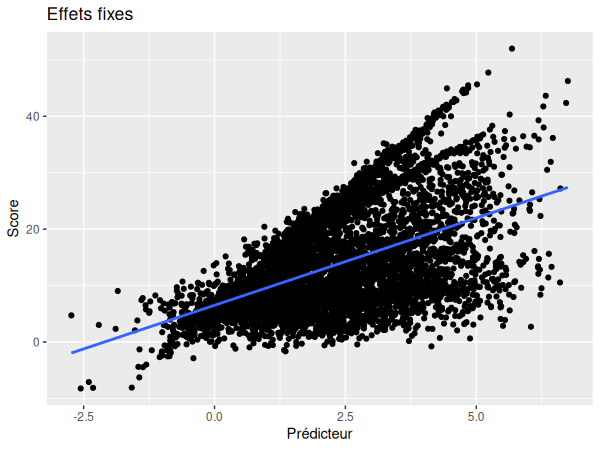
ggplot(data=df, aes(x=predicteur, y=score)) +
geom_point()+
geom_smooth(method=lm, se=F) +
ggtitle("Effets fixes") +
xlab("Prédicteur") +
ylab("Score")
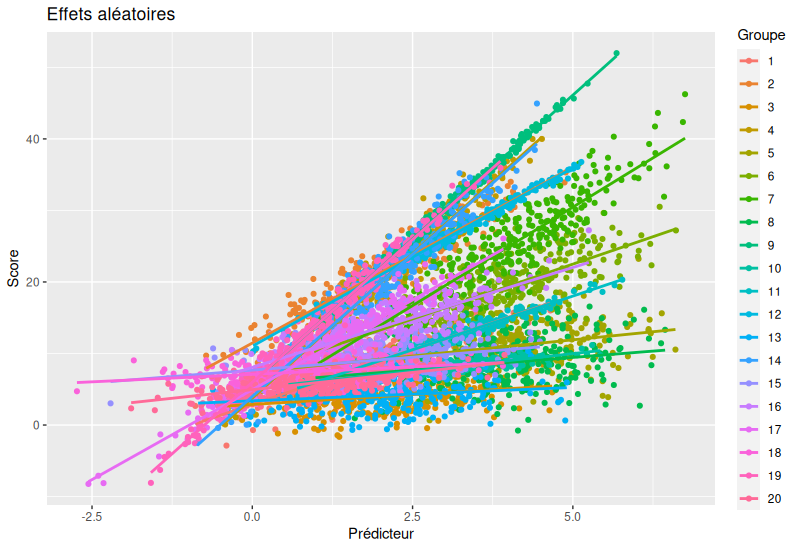
Réalisons maintenant notre modèle de régression:
m <- lmer(score ~ predicteur + (predicteur | groupe), data=df)
Nous devons maintenant vérifier les suppositions de notre modèle de régression:
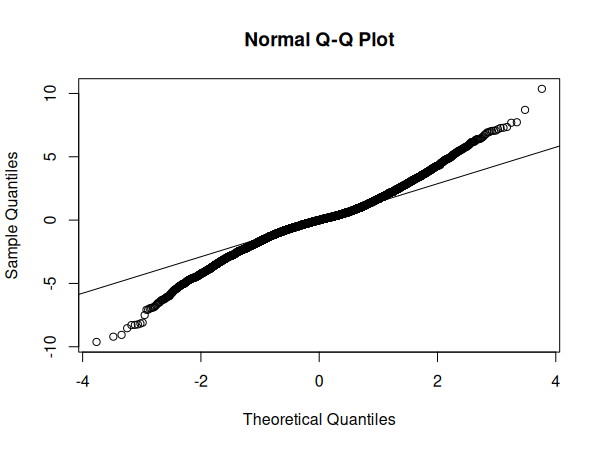
qqnorm(resid(m))
qqline(resid(m))
hist(resid(m))
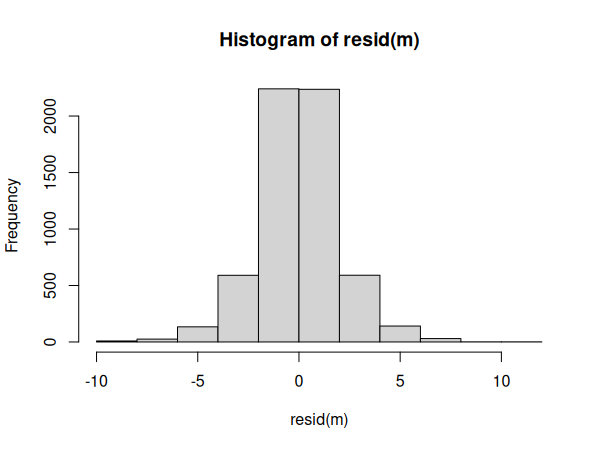
Si le graphique Q-Q ne suit pas tout à fait la ligne centrale, l'histogramme montre toutefois que la distribution des résidus semble parfaitement normale.
Nous pouvons donc passer à l'interprétation des résultats:
summary(m)
Random effects:
| Groups | Name | Variance | Std.Dev | Corr |
|---|---|---|---|---|
| groupe | (Intercept) | 6.340 | 2.518 | |
| predicteur | 8.210 | 2.865 | 0.00 | |
| Residual | 3.828 | 1.957 |
Fixed effects:
| Estimate | Std. Error | df | t value | p | |
|---|---|---|---|---|---|
| (Intercept) | 5.7718 | 0.5675 | 19.0046 | 10.17 | 3.99e-09 *** |
| predicteur | 3.5008 | 0.6412 | 19.0003 | 5.46 | 2.88e-05 *** |